Datenanalyse
2D-Gel Statistik
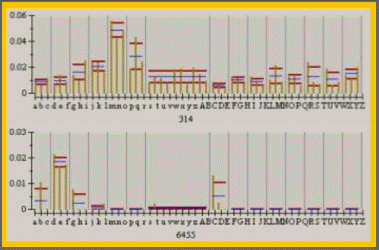
Histogramme der Spotgruppen 314 & 6455, WITA-Proteomics AG: HepG2-Proteom-Datenbank1
Jeder senkrechte Balken steht für das relative Spotvolumen desjenigen Spots, der die Spotgruppe im jeweiligen Gel repräsentiert. Mittelwerte (blaue Linien) und Standardabweichungen (rote Linien) wurden für alle Behandlungsklassen berechnet. Die größte Klasse (10 Gele oberhalb der Spotgruppennummer) umfasst die Gele der Kontrollgruppe.
(Mit freundlicher Genehmigung von Eurogentec SA, Seraing, Belgium)
Bei Proteomics-Projekten zum Auffinden neuer Medikamenten-Wirkorte oder zur Klärung von Reaktionsmechanismen besteht ein wesentliches Etappenziel auf dem Weg zur Identifizierung differentiell exprimierter Proteine darin, eine qualitativ hochwertige d.h. statistisch valide 2D-Gel-Proteomedatenbank zu erhalten. Diese Art des Projektdesigns stellt besondere Anforderungen an die Qualität der Spotquantifizierung und des Spotmatchings.
In der Regel können die %Vol-Mittelwerte individueller Klassen mit +/-30%-Genauigkeit reproduziert werden, wenn angenommen wird, das drei Gelreplikate pro Klasse verwendet werden. Vereinzelte Ausreißer sind auf noch verbleibende Spotdetektions- und Spotmatchingfehler zurückzuführen. Auf diesem Niveau des Spoteditings können jedoch die noch verbleibenden Fehler leicht erkannt werden.
Höhere statistische Genauigkeit kann durch Erhöhung der Zahl der Gele pro Klasse erreicht werden. Vom statistischen Standpunkt aus betrachtet würde ein Minimum von 10 Gelen pro Klasse eine gute Datenbasis liefern. Von den meisten Wissenschaftlern werden jedoch aus Zeit- und Kostengründen in der Regel lediglich 3-5 Gele pro Behandlungsklasse gewählt.
1Thome-Kromer B, Bonk I, Klatt M, Nebrich G, Taufmann M, Bryant S, Wacker U and Köpke A.
TOWARD THE IDENTIFICATION OF LIVER TOXICITY MARKERS: A PROTEOME STUDY IN HUMAN CELL CULTURE AND RATS. Proteomics 2003; 3(10), 1835-62